RAG Architecture (Retrieval-Augmented Generation)
Introduction
Large language models are powerful—but they have a major limitation: they don’t know your data.
That’s where RAG architecture (Retrieval-Augmented Generation) comes in. It combines search and generation to give AI systems access to external knowledge in real time.
Think of it like this: instead of relying purely on memory, your AI gets to look things up before answering.
What is RAG Architecture?
RAG architecture is a design pattern that enhances LLMs by integrating a retrieval step before generating a response.
In simple terms:
- The system retrieves relevant data
- Then the LLM generates an answer using that data
This approach is also known as retrieval augmented generation, and it forms the foundation of modern AI applications like chatbots, copilots, and knowledge assistants.
Why RAG Matters in Modern AI Systems
Traditional LLMs:
- Are trained on static datasets
- Can hallucinate outdated or incorrect information
- Require expensive retraining to update knowledge
With a RAG pipeline, you can:
- Inject fresh, domain-specific data
- Reduce hallucinations
- Avoid costly fine-tuning cycles
This makes RAG a key building block for any LLM retrieval system.
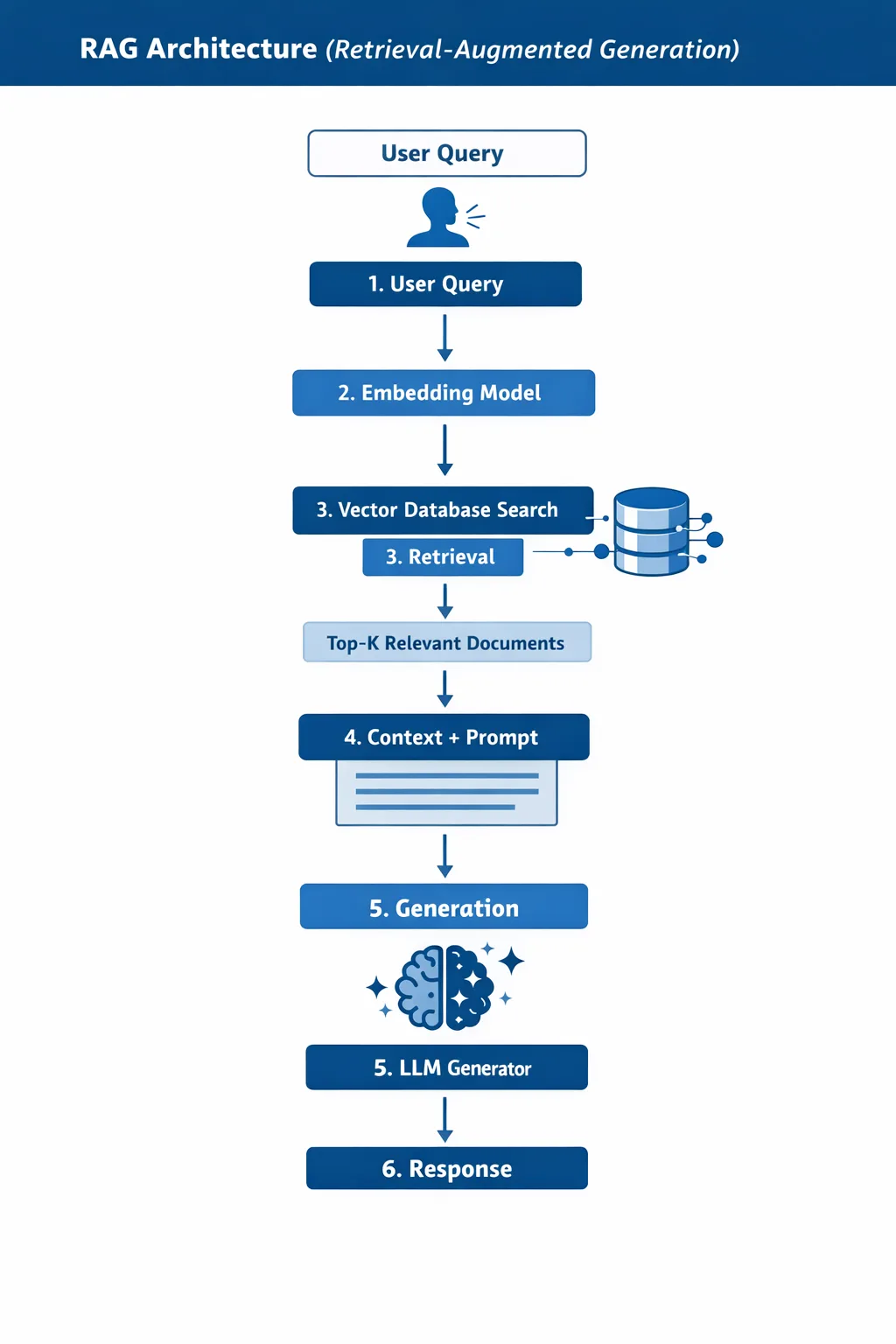
How RAG Works (Step-by-Step Pipeline)
Here’s how a typical RAG pipeline operates:
- User Query
- A user asks a question
- Embedding
- The query is converted into a vector representation
- Retrieval
- The system searches a vector database for relevant documents
- Context Injection
- Retrieved documents are added to the prompt
- Generation
- The LLM generates an answer based on the context
- Response
- The final answer is returned to the user
Simple Diagram (Text Explanation)
Key Components of RAG
1. Retriever
The retriever finds relevant information from your data source.
Common approaches:
- Dense retrieval (embeddings)
- Hybrid search (keyword + vector)
Goal: high recall and relevance
2. Generator (LLM)
This is the language model (e.g., GPT-like models).
It:
- Takes the retrieved context
- Produces a natural language response
3. Vector Database
A vector database stores embeddings and enables fast similarity search.
Popular options:
- Pinecone
- Weaviate
- FAISS
4. Embeddings
Embeddings convert text into numerical vectors.
They allow:
- Semantic search (not just keyword matching)
- Context-aware retrieval
RAG vs Fine-Tuning
A common question: RAG vs fine-tuning — which is better?
Key Differences
| Aspect | RAG Architecture | Fine-Tuning |
|---|---|---|
| Data updates | Real-time | Requires retraining |
| Cost | Lower | Higher |
| Flexibility | High | Limited |
| Use case | Dynamic knowledge | Behavior/style changes |
When to Use RAG
- Frequently changing data
- Large knowledge bases
- External documents (PDFs, APIs)
When to Use Fine-Tuning
- Tone/style control
- Domain-specific reasoning patterns
- Structured output formats
👉 In practice, many systems combine both.
Real-World Use Cases
Here are common RAG use cases:
1. AI Chatbots with Knowledge Base
- Customer support bots
- Internal company assistants
2. Developer Copilots
- Codebase-aware assistants
- Documentation Q&A
3. Search Engines
- Semantic enterprise search
- Legal or medical document retrieval
4. Content Generation
- AI writing tools grounded in real data
- SEO content assistants
Benefits and Limitations
Benefits
- ✅ Reduces hallucinations
- ✅ Real-time knowledge updates
- ✅ No need for retraining
- ✅ Works with private data
Limitations
- ❌ Retrieval quality affects output
- ❌ Latency can increase
- ❌ Requires data preprocessing
- ❌ Context window limits
Best Practices for Building RAG Systems
1. Optimize Chunking
- Split documents into meaningful chunks (200–500 tokens)
2. Use Hybrid Search
- Combine keyword + vector search for better results
3. Reranking
- Apply a second model to refine top results
4. Prompt Engineering
- Clearly instruct the LLM to use provided context
5. Monitor Performance
- Track:
- Retrieval accuracy
- Response quality
- Latency
Tools & Technologies
Here are popular tools for building RAG architecture:
Frameworks
- LangChain
- LlamaIndex
Vector Databases
- Pinecone
- Weaviate
- Chroma
Embedding Models
- OpenAI embeddings
- Hugging Face models
Example: Simple RAG Pipeline (JavaScript)
// Pseudo-code for a simple RAG pipeline
const query = "What is RAG architecture?";
// Step 1: Embed query
const queryEmbedding = embed(query);
// Step 2: Retrieve documents
const docs = vectorDB.search(queryEmbedding, { topK: 3 });
// Step 3: Build prompt
const context = docs.map(d => d.text).join("\n");
const prompt = `
Answer the question using the context below:
${context}
Question: ${query}
`;
// Step 4: Generate response
const answer = llm.generate(prompt);
console.log(answer);FAQ
1. What is RAG architecture in simple terms?
It’s a system where an AI retrieves relevant data before generating an answer.
2. Is RAG better than fine-tuning?
Not always. RAG is better for dynamic data, while fine-tuning is better for behavior and style.
3. What are vector databases used for in RAG?
They store embeddings and allow fast similarity search to find relevant documents.
4. Can RAG eliminate hallucinations completely?
No, but it significantly reduces them when retrieval quality is high.
5. What is the biggest challenge in RAG systems?
Ensuring high-quality retrieval and relevant context selection.
Conclusion
RAG architecture is quickly becoming the standard for building intelligent, reliable AI systems.
By combining retrieval with generation, it bridges the gap between static models and real-world knowledge.
Looking ahead, we’ll likely see:
- Smarter retrieval techniques
- Better hybrid systems (RAG + fine-tuning)
- More real-time AI applications
If you’re building AI products today, mastering retrieval augmented generation is no longer optional—it’s essential.